Abstract
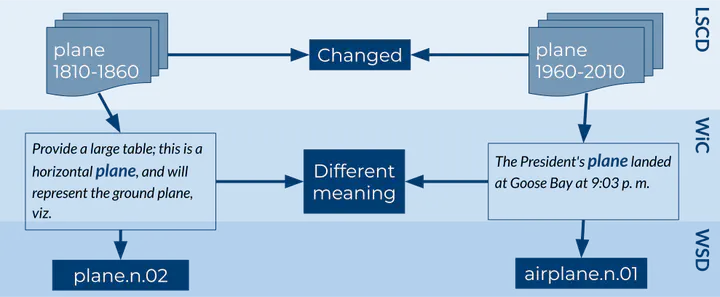
The recent introduction of large-scale datasets for the WiC (Word in Context) task enables the creation of more reliable and meaningful contextualized word embeddings. However, most of the approaches to the WiC task use cross-encoders, which prevent the possibility of deriving comparable word embeddings. In this work, we introduce XL-LEXEME, a Lexical Semantic Change Detection model. XL-LEXEME extends SBERT, highlighting the target word in the sentence. We evaluate XL-LEXEME on the multilingual benchmarks for SemEval-2020 Task 1 - Lexical Semantic Change (LSC) Detection and the RuShiftEval shared task involving five languages: English, German, Swedish, Latin, and Russian. XL-LEXEME outperforms the state-of-the-art in English, German and Swedish with statistically significant differences from the baseline results and obtains state-of-the-art performance in the RuShiftEval shared task.